Optimisation is often doing fewer things
We recently migrated Le Temps, the most famous media in the French-speaking part of Switzerland, to Ruby on Rails. Yay!
Among an infinite list of tasks, we had a very low-priority issue to create archive pages. They list all articles ever written, ordered per month. Their single purpose is to make it easy for search engines to index the website. No human is supposed to visit archives, only robots. And bots never complain, so who cares? Not us. We were so busy with other more important matters.
But as it usually happens when we don't care enough, we pay for it later. It didn't take too long.
As it turns out, some robots scan those archive pages every few hours at a rate between 100 and 300 requests per minute. It's not that much. But when those response times are between 10 and 60 seconds, it's way too much. The search engine might cause a denial of service, and no human could access during the indexing, and humans do complain.
Finding the bottleneck
Let's have a look at the code causing the troubles. The controller is super simple, and the view is just a loop printing a link to each article.
class ArchivesController < ApplicationController
def show
@articles = Article::published_between(start_of_month, end_of_month)
end
end
So, where is the bottleneck? That's easy to find since we use RorVsWild, our APM tool for Rails. We were lucky to know what was happening before too many people noticed.
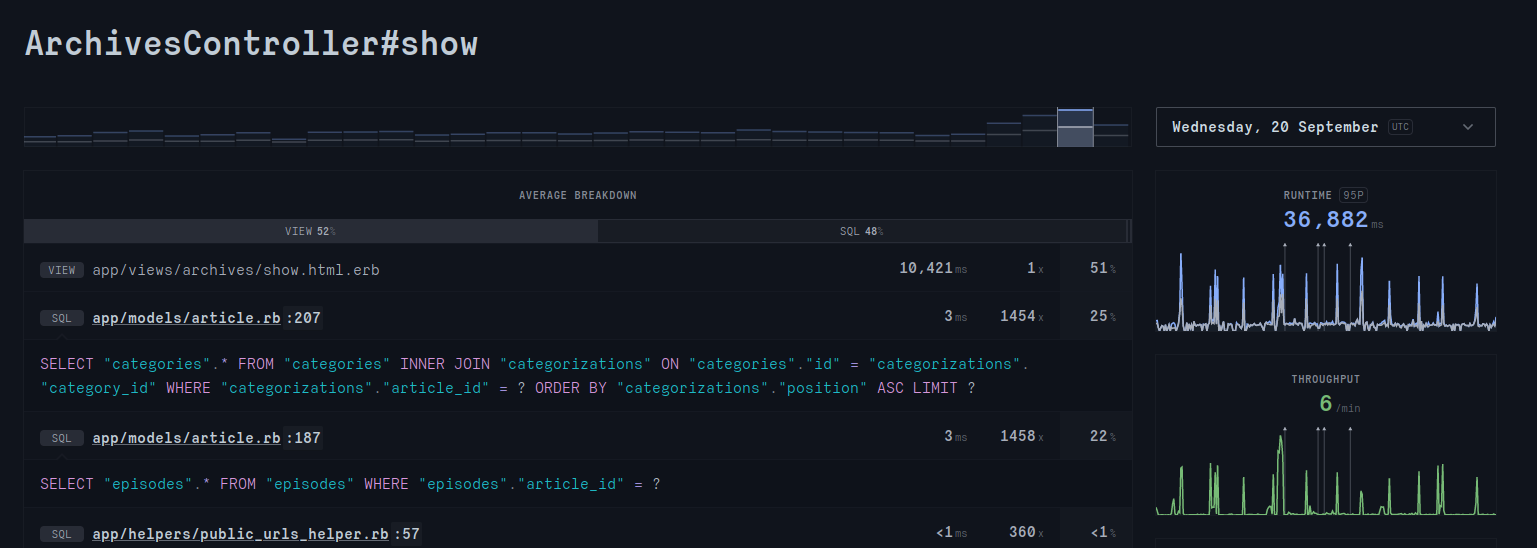
We can see that roughly every two hours, there are some traffic spikes, and in between, less than a request per minute. Half the time occurs in the view where the SQL request is triggered to instantiate thousands of ActiveRecord instances. The other half occurs in an N+1 query problem where we retrieve a category or a series episode for every article, as their URLs depend on them.
What we have to do then is straightforward:
- To avoid instantiating thousands of ActiveRecord objects
- To avoid N+1 queries
Skipping ActiveRecord instances
ActiveRecord instances are convenient. They can be slow because they are doing many things. In this particular case, we don't need much of its features. So, the idea is to load only the data we need into PORO (Plain Old Ruby Object) and implement a few methods to generate proper URLs for articles.
class Article::Archive
attr_reader :id, :title, :path, :category_id, :series_id
def self.published_between(from_date, to_date)
select = <<-SQL
id,
title,
path,
-- An article has and belongs to many categories
(SELECT category_id FROM categorizations WHERE article_id = articles.id ORDER BY position LIMIT 1)
SQL
rows = Article.published_between(from_date, to_date).pluck(Arel.sql(select))
rows.map { |row| new(*row) }
end
def initialize(id, title, path, category_id)
@id = id
@title = title
@path = path
@category_id = category_id
end
def category
Category.find(category_id) # We still have the N+1 query issue here
end
def to_param
path # to_param is called by URL helpers
end
end
We are using pluck to return raw results from the database.
Thus, it's much faster than instanciating Article instances as it only initializes four instance variables.
Moreover, with the subquery, we are already retrieving the category ID of an article.
We have to do it through a subquery because an article has and belongs to many categories.
The category method is needed to prefix the URL path with the category name.
Finally, we implement to_param to work with URL helpers.
Avoiding N+1 queries
We still have the N+1 query problem where a query is triggered to retrieve the category of each article.
The typical way to solve this issue is to use Article.includes(:categories) to fetch all categories in one query.
However, we can't access it since we no longer manipulate an ActiveRecord instance but our own Article::Archive object.
Moreover, there are less than 100 categories for thousands of articles.
That means includes would have instantiated many duplicated categories, which is suboptimal.
So, the idea is to load all categories into a hash and use it as a cache.
The code above introduces the cache_categories method.
class Article::Archive
attr_reader :id, :title, :path, :category_id, :series_id
def self.published_between(from_date, to_date)
cache_categories # Load upfront all categories
select = <<-SQL
id,
title,
path,
-- An article has and belongs to many categories
(SELECT category_id FROM categorizations WHERE article_id = articles.id ORDER BY position LIMIT 1)
SQL
rows = Article.published_between(from_date, to_date).pluck(Arel.sql(select))
rows.map { |row| new(*row) }
end
def self.cache_categories
@@categories = Category.all.reduce({}) { |h, c| h.update(c.id => c) }
end
def initialize(id, title, path, category_id)
@id = id
@title = title
@path = path
@category_id = category_id
end
def category
@@categories[category_id] # N+1 query solved !
end
def to_param
path
end
end
Conclusion
After deploying we can enjoy watching the response time decreasing.
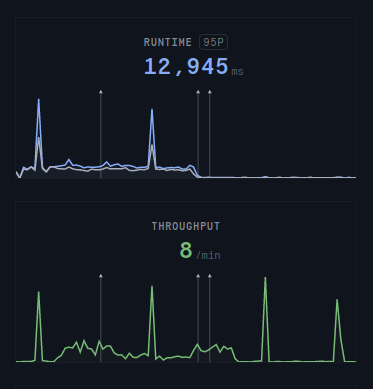
As the title said, doing less is always faster. The optimisation was pretty simple. It actually took me more time to write this article than to code the optimisation.
Next step would be to cache theses pages, because fetching thousands of records it still a lot of work.
If you like this article, you might also like my Ruby on Rails monitoring service.