Fast text search with PostgreSQL in a Rails project
I build Ruby on Rails applications at Base Secrète with my partner Antoine. Once upon a time, some famous journalists reached us for a rescue mission. We had to take over the code produced by a previous team before they even launched. They already had invested a lot of money and nothing was working properly. We managed to fix and develop what was needed in a rush, avoiding to touch some less critical parts of the application.
One of the first things we do, is to install our own monitoring tool, RorVsWild, on all the applications we work on. It makes it easy to monitor all our apps and be aware of performances issues and errors before our clients do. It lets us show and explain our clients why we should prioritise optimisations over new features.
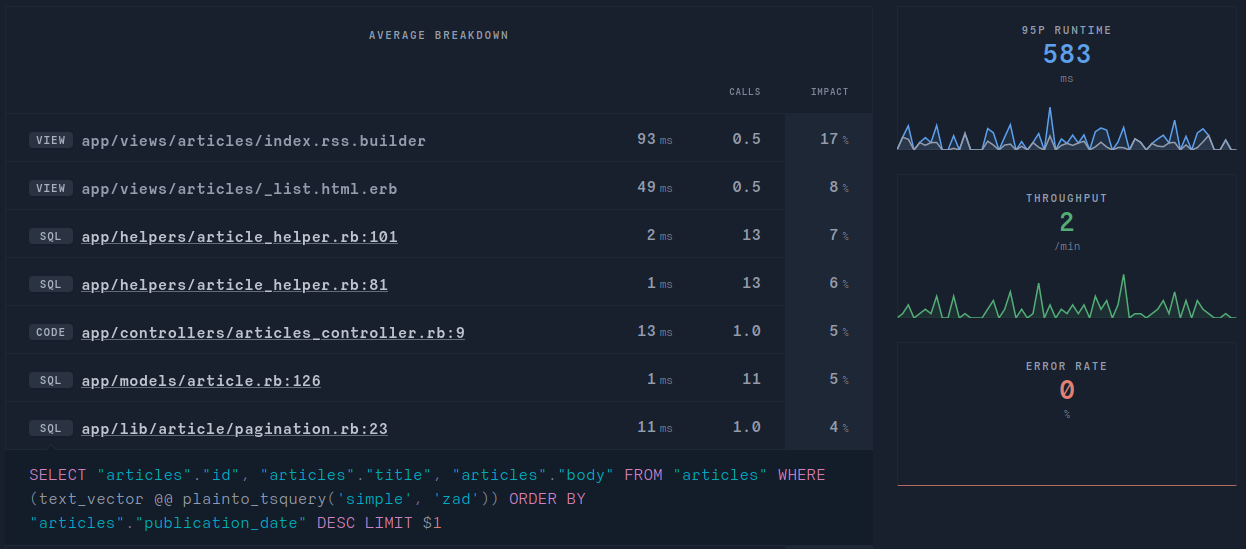
As this media website became quite popular, and as the database grew, some issues started to arise. Preparing for a product development call with them, we checked what where the most pressing technical issues and noticed this in RorVsWild:
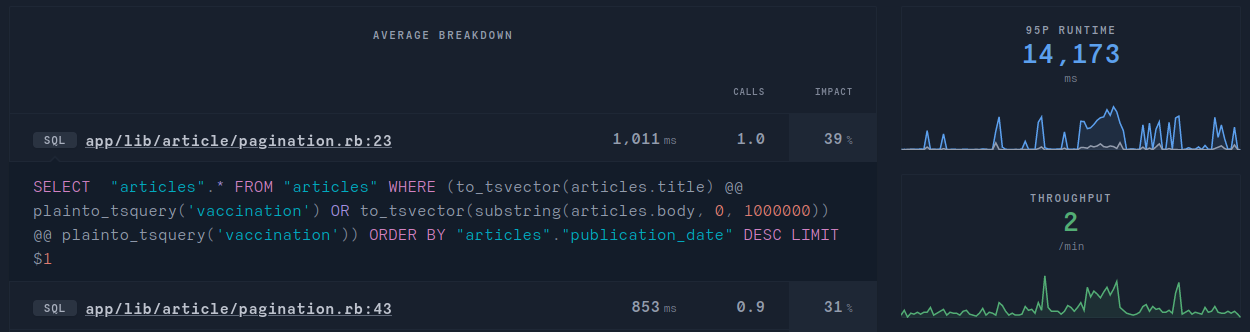
FOURTEEN seconds ... that’s much more than the time needed for a regular human to declare your site is broken. It’s totally unacceptable. Thanks to RorVsWild the bottleneck is easily found. It’s the SQL query in pagination.rb on line 23.
We will see how to optimise this unefficient query. In the first part we will only focus at the SQL level, then I will give an example to apply it into a Rails application.
Optimizing PostgreSQL text search
Let’s start with the table definition :
\d articles
Table "public.articles"
Column | Type | Collation | Nullable | Default
------------------------+-----------------------------+-----------+----------+--------------------------------------
id | bigint | | not null | nextval('articles_id_seq'::regclass)
title | character varying | | |
body | text | | |
Indexes:
"articles_pkey" PRIMARY KEY, btree (id)In our example we are only interested in searching through the body text. Let's see how fast it is against a large corpus :
EXPLAIN ANALYZE SELECT count(*) FROM "articles" WHERE (to_tsvector(body) @@ plainto_tsquery('simple', 'test'));
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Aggregate (cost=3546.74..3546.76 rows=1 width=8) (actual time=6523.238..6523.239 rows=1 loops=1)
-> Seq Scan on articles (cost=0.00..3546.62 rows=48 width=0) (actual time=3.214..6522.726 rows=1200 loops=1)
Filter: (to_tsvector(body) @@ '''test'''::tsquery)
Rows Removed by Filter: 8490
Planning Time: 0.210 ms
Execution Time: 6523.299 ms
(6 rows)
Time: 6525.133 ms (00:06.525)Without surprise the naive implementation is very slow and the query plan show us that PostgreSQL scan the entire table. Indeed it's slow because PostgreSQL has to convert the whole corpus into a text vector for each query and moreover, there is no index.
I just note here that I'm using the simple dictionnary. In the case the application handle articles in different languages this is the best trade off I have found. They are special rules for each languages and indexes work with only one language.
The first step is to add a column which will contain the text vector:
ALTER TABLE articles ADD COLUMN text_vector tsvector;
tsvector_update_trigger(text_vector, 'simple', body);The trigger automatically synchronizes the text vector on each write. It's possible to concatenate more columns (such as the title). This can be also achieved manually at the application level if your prefer (we will see an example in the next part). Let's see how of much faster it is :
EXPLAIN ANALYZE SELECT count(*) FROM "articles" WHERE (text_vector @@ plainto_tsquery('simple', 'test'));
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Aggregate (cost=1124.24..1124.25 rows=1 width=8) (actual time=9.719..9.721 rows=1 loops=1)
-> Seq Scan on articles (cost=0.00..1124.12 rows=48 width=0) (actual time=9.710..9.711 rows=0 loops=1)
Filter: (text_vector @@ '''test'''::tsquery)
Rows Removed by Filter: 9690
Planning Time: 0.320 ms
Execution Time: 9.792 ms
(6 rows)
Time: 11.099 msThe query went down from 6625ms to 11ms, which is really great. The query plan shows that PostgreSQL doesn't have to translate the corpus into a text vector. However it still needs to scan the whole table. We can keep improving by adding a gin index :
CREATE INDEX search_index ON article USING gin(to_tsvector('simple', body));
EXPLAIN ANALYZE SELECT count(*) FROM "articles" WHERE (text_vector @@ plainto_tsquery('simple', 'test'));
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=174.57..174.58 rows=1 width=8) (actual time=0.022..0.024 rows=1 loops=1)
-> Bitmap Heap Scan on articles (cost=16.38..174.45 rows=48 width=0) (actual time=0.016..0.017 rows=0 loops=1)
Recheck Cond: (text_vector @@ '''test'''::tsquery)
-> Bitmap Index Scan on index_articles_on_text_vector (cost=0.00..16.36 rows=48 width=0) (actual time=0.011..0.012 rows=0 loops=1)
Index Cond: (text_vector @@ '''test'''::tsquery)
Planning Time: 0.357 ms
Execution Time: 0.090 ms
(7 rows)
Time: 1.151 msThe query is 10 times faster thanks to the index and it take only 1.5ms which is really nice. The query plan shows that after the index scan, only 48 rows are read to check the condition. We have seen how to perform fast text search with PostgreSQL. The next part is to handle it properly in a Rails application.
How does it looks in a rails application ?
To make things a little bit more interesting, we will suppose that the the text vector synchronization is handled at the application level. Here a sample model Article with some comments to avoid traps :
class Article < ApplicationRecord
# Rails have to simply ignore the text_vector column, otherwise it will be anoying and counter productive
self.ignored_columns = [:text_vector]
scope :text_search, -> (query) { where("text_vector @@ plainto_tsquery('simple', ?)", query) }
# Trigger text vector synchronization on each save
around_save :update_text_vector_on_save
def update_text_vector_on_save
# Update the text vector only when data has changed
if (title_changed? || body_changed?) && yield
# Concatenate title and body even if one field is null
cols = ["title", "body"].map { |col| "COALESCE(#{col}, '')" }.join(" || E'\\n' || ")
# Text vector are limited to 1048575 bytes, so text is arbitrary sliced at 1 million characters
# However I have no idea if it's enough in case of high unicodes characters.
Article.where(id: id).update_all("text_vector = to_tsvector('simple', substring(#{cols}, 0, 1000000))")
end
end
endFinally after deployment everythings looks much faster. The 95th percentile response time is down to 583ms !